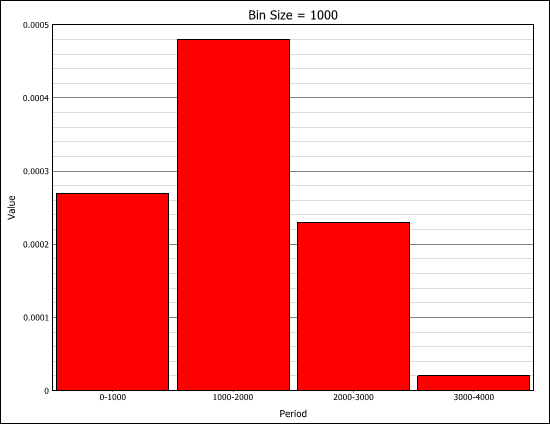
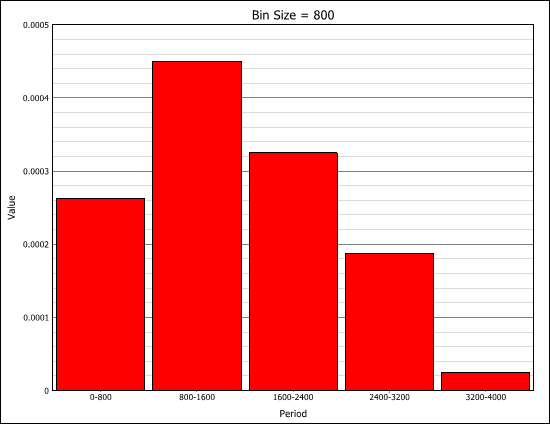
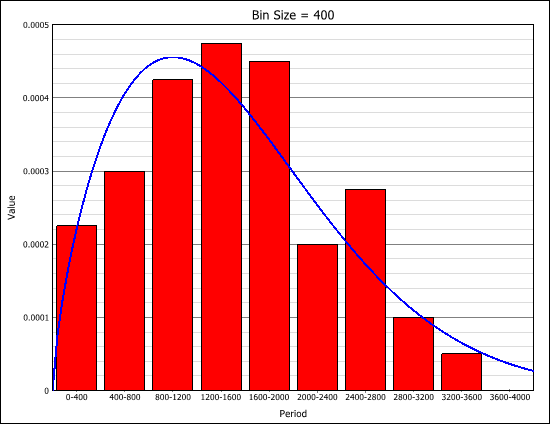
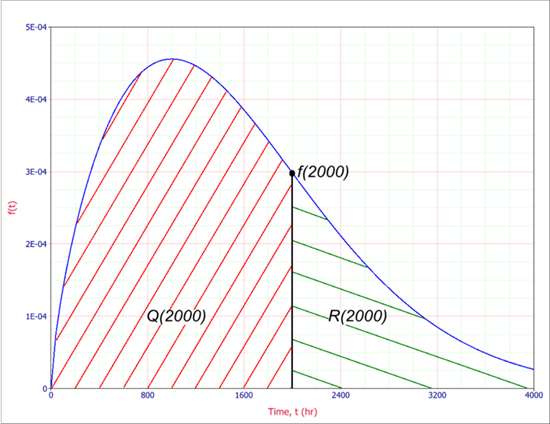
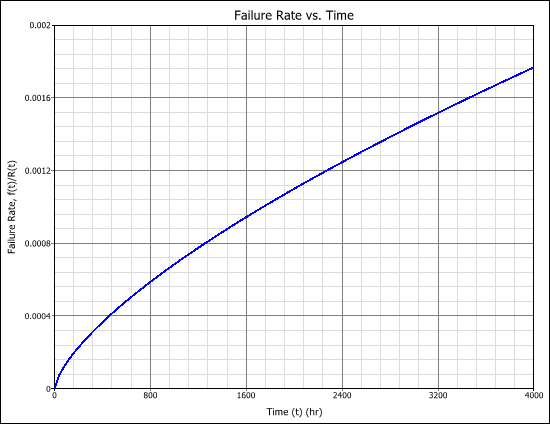
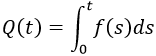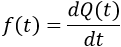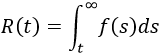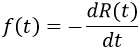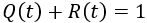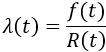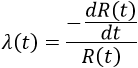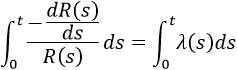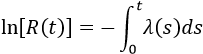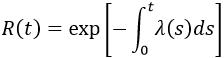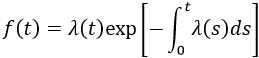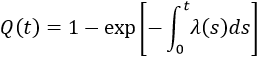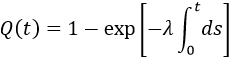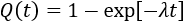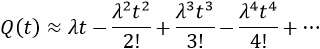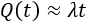This approximation still exists in some reliability textbooks and standards. Although it was a useful approximation when it was first presented, it applies only for a constant failure rate model and only when the product λt is small.
A comparison between the approximation and the actual probability of failure is shown in Table 1, where the value of the failure rate is 0.001 failing/hour (which equates to a mean time to failure of 1000 hours). Assume that the objective of an analysis is to determine the unreliability at the end of a 300-hour product warranty. Using the approximation based on failure rate and time, we would calculate an estimate that is 15% higher than using the unreliability equation itself.