The mean life function, such as the mean time to failure (MTTF), is widely used as the measurement of a product's reliability and performance. This value is often calculated by dividing the total operating time of the units tested by the total number of failures encountered. This metric, which is valid only when the data is exponentially distributed (a poor assumption which implies that the failure rate is constant), is then used as the sole measure of a product's reliability.
One problem that arises from the use of this metric stems from confusion over the differentiation between the "mean" and the "median" values of a data set. The mean is what would normally be called the average, or the most likely value to be expected in a group of data. The mathematical definition is:
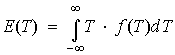
where f(T) is the probability density function of the data. The median, on the other hand, is the value that splits the data. Half of the data will be greater than the median and half will be less than the median. The mathematical definition of the median involves solving the equation:
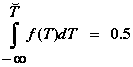
for 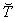
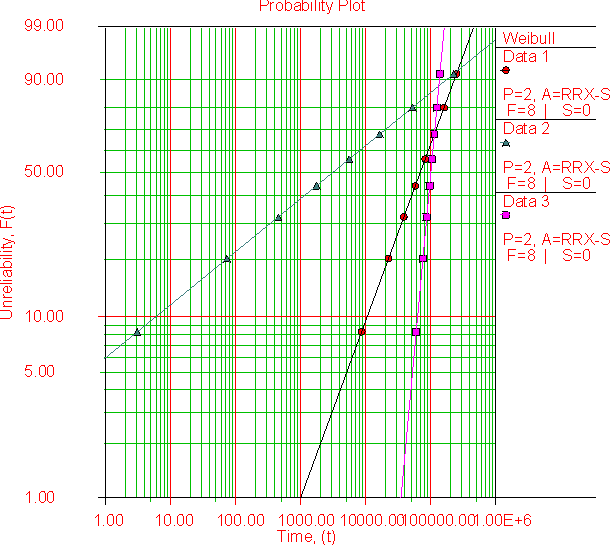
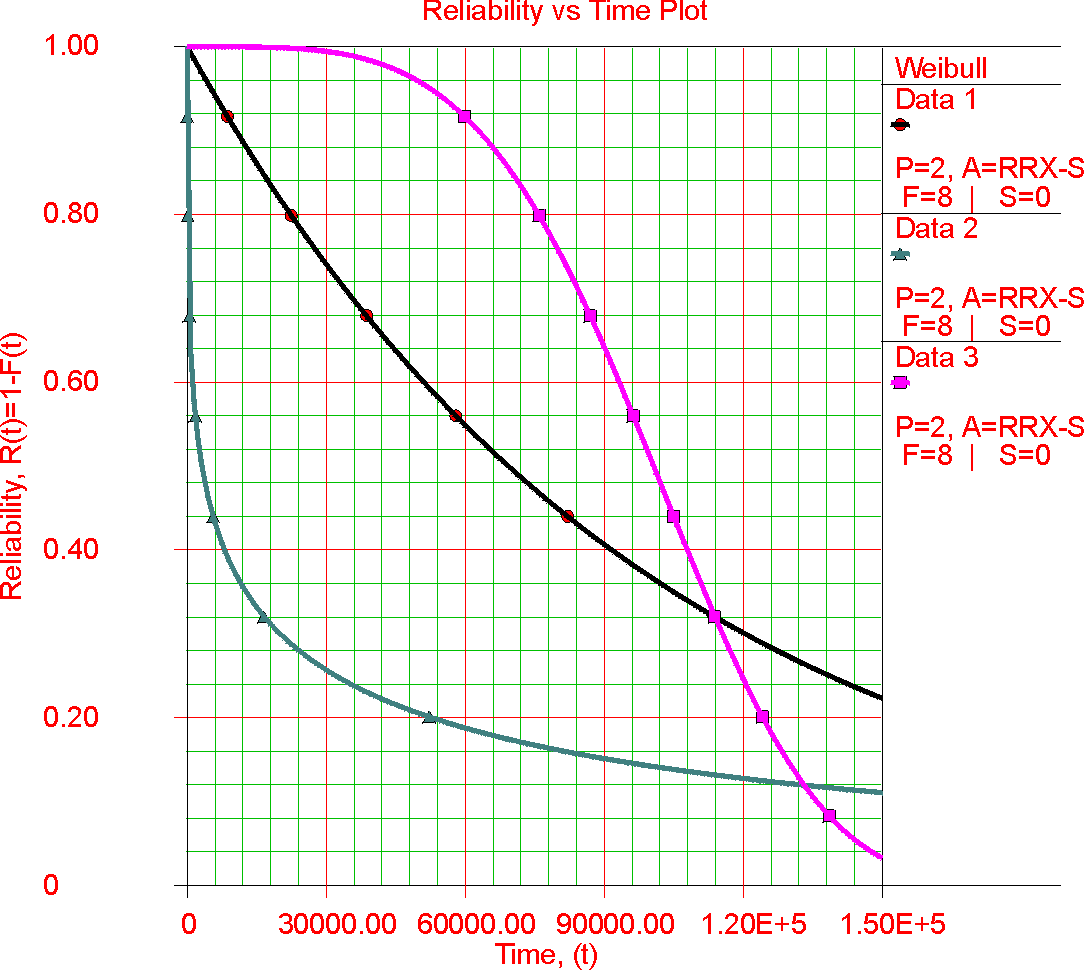
where f(T) is the probability density function of the data. If the data in question is from a symmetrical distribution, such as the normal or Gaussian distribution, the values for the mean and median are equal. However, when dealing with an asymmetrical distribution, such as the exponential or Weibull, there can be a large difference between the mean and median.
To give a discreet example, suppose we have a data set consisting of five values: (1,2,3,4,100). The mean value of this data set is (1+2+3+4+100)/5=110/5=22. However, the median value for this data set is 3, as it is the "middle number" in the set of five. Clearly, there is a sizable difference in the values of the mean and the median for this data set.