Product validation testing is an important step in the design process. The goal of validation or durability tests is to prove that the part is indeed capable of withstanding the loading that it will see in service. These tests are often the last step before approving the part for production. This means the tests are crucial to understanding both the durability and reliability of the product.
Durability tests are often run in the controlled environment of the test lab, and can be specified in a number of ways. Typically, these test specifications are built around the concept of specified excitation or loading over a prescribed duration. The test spec may call for quasi-static loading (i.e., time-independent loading in which inertial effects can be ignored) or dynamic loading (i.e., time-dependent loading in which inertial effects are important). Note that it is important to ensure that the loading in the lab creates the same failure modes as one would expect in the field.
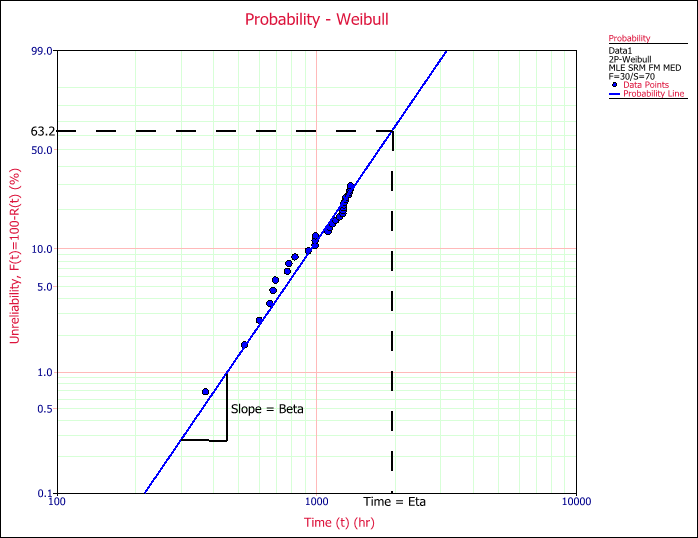
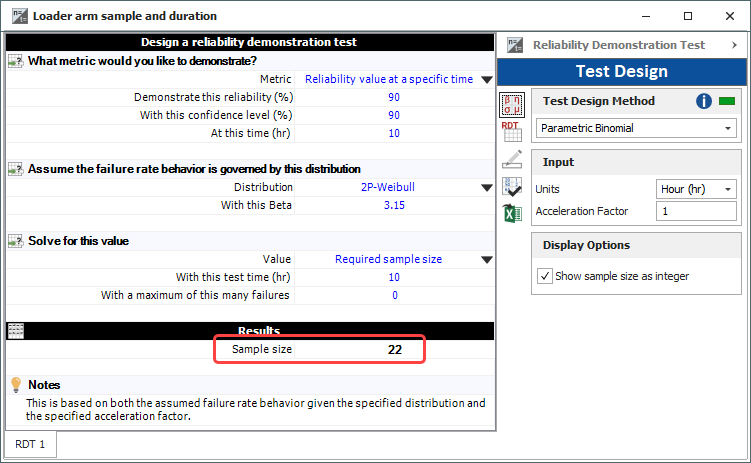
Validation tests need to be correlated to service loading. This correlation can be quantified using the concept of fatigue damage equivalence, in which the loading profile described in the lab test spec is tailored so that the test specimens will accumulate the same fatigue damage as the product sees in service. This fatigue damage correlation allows us to 1) link test time to service life time, so a potential failure in the lab can be correlated to hours or miles in the hands of the customer, and 2) replicate long service lives in a short test duration.
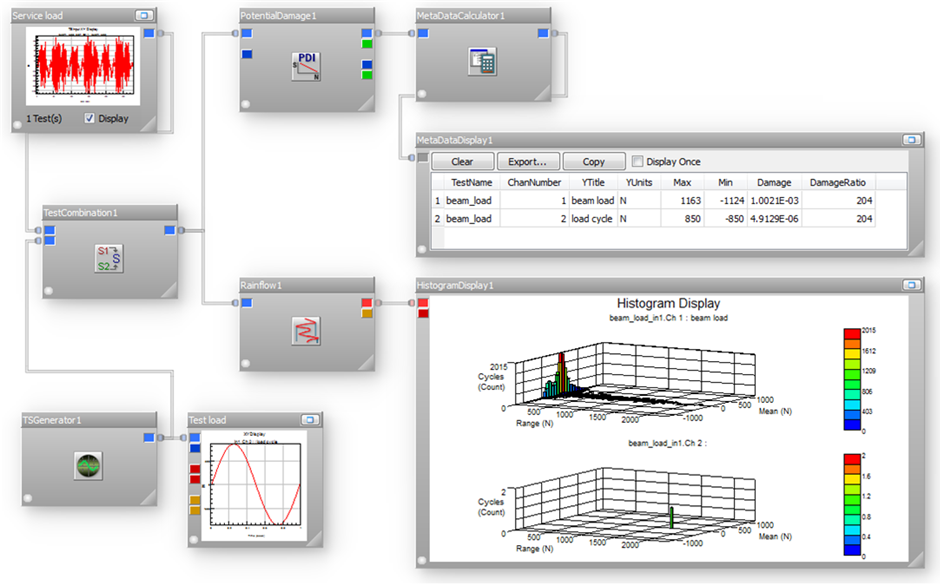
nCode GlyphWorks durability analysis software includes a number of tools to quickly and efficiently reduce complicated service loading into an equivalent damage test spec. For example, consider a product like a lifting implement that is subject to cyclic loading. This loading can be measured in service and used to define the durability test spec.
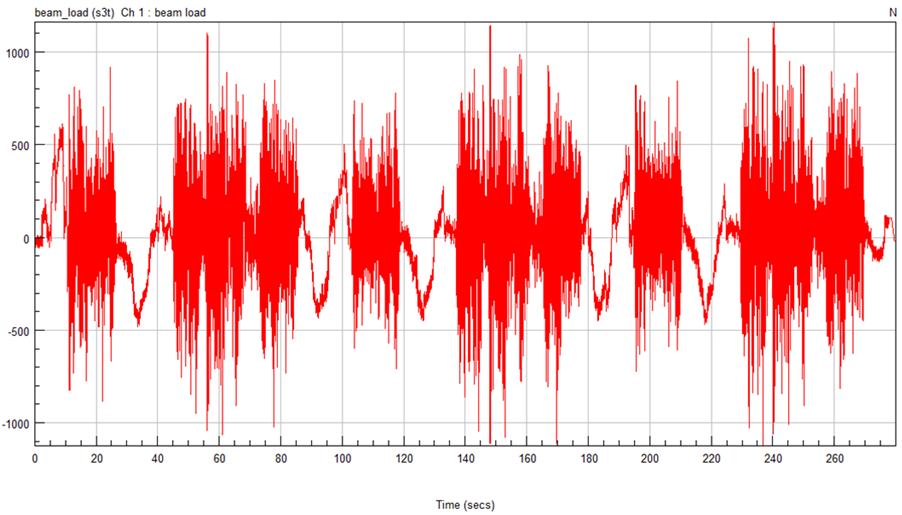
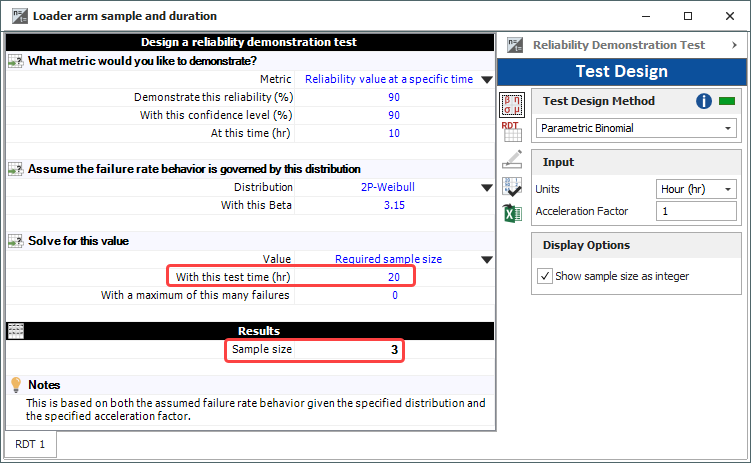
The measured service loading looks like this: