arrow_back_ios
Main Menu
arrow_back_ios
Main Menu
- Accessories
- Actuators
- Combustion Engines
- Durability
- eDrive
- Mobile Systems
- Production Testing Sensors
- Transmission Gearboxes
- Turbo Charger
- DAQ Systems
- High Precision and Calibration Systems
- Industrial electronics
- Power Analyser
- S&V Hand-held devices
- S&V Signal conditioner
- Wireless DAQ Systems
- Head and torso simulators (HATS)
- Artificial ears
- Electroacoustic hardware
- Bone conduction
- Electoacoustic software
- Accessories old
- Pinnae
- Accessories
- DAQ
- Drivers API
- nCode - Durability and Fatigue Analysis
- ReliaSoft - Reliability Analysis and Management
- Test Data Management
- Utility
- Vibration Control
- Inertial Sensor Software
- Acoustic
- Current / voltage
- Displacement
- Force
- Inertial Sensors
- Load Cells
- Multi Component Sensors
- Pressure
- Strain
- Temperature Sensors
- Tilt Sensors
- Torque
- Vibration
- Exciters
- Articles
- Case Studies
- Recorded Webinars
- Presentations
- Primers and Handbooks
- Videos
- Whitepapers
- Search all resources
- Acoustics
- Asset & Process Monitoring
- Custom Sensors
- Data Acquisition & Analysis
- Durability & Fatigue
- Electric Power Testing
- Machine automation control and navigation
- NVH
- Reliability
- Smart Sensors
- Vibration
- Virtual Testing
- Weighing
- Aerospace & Defence
- Audio
- Automotive & Ground Transportation
- Energy
- Robotics
- Vibration testing - Industries
- Calibration
- HBK Assured Service Contracts
- Installation, Maintenance & Repair
- Fatigue Testing Lab & Materials Characterisation - HBK
arrow_back_ios
Main Menu
- Bridge Calibration Units
- Microphone Calibration System
- Sound Level Meter Calibration System
- Strain Gauge Precision Instrument
- Vibration Transducer Calibration System
- Accessories
- BK Connect Pulse
- catman Enterprise
- catmanEasy AP
- Software Downloads for Perception / Genesis HighSpeed
- Tescia
- ReliaSoft BlockSim
- ReliaSoft Cloud
- ReliaSoft Lambda Predict
- ReliaSoft Product Suites
- ReliaSoft RCM++
- ReliaSoft XFMEA
- ReliaSoft XFRACAS
- ReliaSoft Weibull++
- Classical Shock
- Random
- Random-On-Random
- Shock Response Spectrum Synthesis
- Sine-On-Random
- Time Waveform Replication
- Vibration Control Software
- Microphone sets
- Cartridges
- Reference Microphones
- Special Microphones
- Acoustic Material Testing Kits
- Acoustic Calibrators
- Hydrophones
- Microphone Pre-amplifiers
- Sound Sources
- Accessories for acoustic transducers
- Inertial Measurement Units (IMU)
- Vertical Reference Units (VRU)
- Attitude and Heading Reference Systems (AHRS)
- Inertial Navigation Systems (INS)
- Inertial Sensors Accessories
- Bending / beam
- Canister
- Compression
- Single Point
- Tension
- Weighing Modules
- Digital load cells
- Accessories
- Accessories
- Experimental testing
- Fiber Optic Technology
- Transducer Manufacturing (OEM)
- Strain Sensors
- Accessories
- CCLD (IEPE) accelerometers
- Charge Accelerometers
- Fiber Optic Accelerometers
- Force transducers
- Reference accelerometers
- Impulse hammers / impedance heads
- Tachometer Probes
- Vibration Calibrators
- Cables
- Accessories
- Acoustics and Vibration
- Asset & Process Monitoring
- Data Acquisiton
- Electric Power Testing
- Fatigue and Durability Analysis
- Mechanical Test
- Reliability
- Weighing
- Electroacoustics
- Noise Source Identification
- Handheld S&V measurements
- Sound Power and Sound Pressure
- Noise Certification
- Acoustic Material Testing
- OEM Custom Sensor Assemblies for eBikes
- OEM Custom Sensor Assemblies for Agriculture Industry
- Custom Sensor Assemblies for Robotic OEM
- OEM Custom Sensor Assemblies for Medical
- Automotive Structural Durability and Fatigue Testing
- Durability Simulation & Analysis
- Material Fatigue Characterisation
- Electrical Devices Testing
- Electrical Systems Testing
- Grid Testing
- High-Voltage Testing
- End of Line Durability Testing
- Process Weighing
- Sorting and Batching Solutions
- Scale Manufacturing Solutions
- Vehicle Scale Solutions
- Filling, Dosing and Checkweighing Control
- Agricultural Robots
- Collaborative Robots (Cobots)
- Industrial Robots
- Medical, Surgical, & Healthcare Robots
- Mobile Robots
arrow_back_ios
Main Menu
- Housing
- Communication processor
- Amplifier modules
- Connection boards
- Special function modules
- Accessories
- G-Link-200
- G-Link-200-OEM
- SG-Link-200
- SG-Link-200-OEM
- V-Link-200
- RTD-Link-200
- TC-Link-200
- TC-Link-200-OEM
- Free-field Microphone Cartridges
- Pressure-field Microphone Cartridges
- Diffuse-field Microphone Cartridges
- Binaural Audio
- Outdoor microphones
- Probe Microphones
- Sound intensity probes
- Surface microphone
- Array microphones
- Other special microphone
- Production line test
- Microphone cables
- Tripods
- Microphone booms
- Microphone adapters
- Electroacoustic actuators
- Microphone Windscreens
- Nose cones
- Microphone holders
- Tripods
- Other accessories for acoustic transducers
- Microphone outdoor protection
- Rod end bearings
- Tensile load introductions
- Thrust pieces and load buttons
- Cables and connectors
- Screw sets
- Load base / Tensile compressive adapter
- Measurement Cables
- Ground cables
- Thrust pieces
- Bearings
- Load feet
- Base plates
- Knuckle eyes
- Adapters
- Mouting aids and others
- Adhesives
- Protective coatings
- Cleaning material
- SG Kits
- Solder terminals
- Other
- Cables
- ZeroPoint Balancing
- TCS balancing
- TCO balancing
- Magnets
- Mounting clips/bases
- Studs, screws and washers
- Adhesives/Tools
- Adapters
- Mechanical filters
- Other accessories
- Testing Of Hands-Free Devices
- Smart Speaker Testing
- Speaker Testing
- Hearing Aid Testing
- Headphone Testing
- Soundbar Testing
- Telephone Headset And Handset Testing
- Acoustic Holography
- Acoustic Signature Management
- Underwater Acoustic Ranging
- Wind Tunnel Acoustic Testing – Aerospace
- Wind Tunnel Testing For Cars
- Beamforming
- Flyover Noise Source Identification
- Real-Time Noise Source Identification With Acoustic Camera
- Sound Intensity Mapping
- Spherical Beamforming
- Product Noise
- Shock and Drop Testing
- Environmental Stress Screening - ESS
- Package Testing
- Buzz, Squeak and Rattle (BSR)
- Mechanical Satellite Qualification - Shaker Testing
- Operating Deflection Shapes (ODS)
- Classical Modal Analysis
- Ground Vibration Test (GVT)
- Operational Modal Analysis (OMA)
- Structural Health Monitoring (SHM)
- Test-FEA Integration
- Shock Response Spectrum (SRS)
- Structural Dynamics Systems
- Force Calibration
- Torque Calibration
- Microphones & Preamplifiers Calibration
- Accelerometers Calibration
- Pressure Calibration
- Displacement Sensor Calibration
- Sound Level Meter Calibration
- Sound Calibrator & Pistonphone Calibration
- Vibration Meter Calibration
- Vibration Calibrator Calibration
- Noise Dosimeter Calibration
- QuantumX Calibration
- Genesis HighSpeed Calibration
- Somat Calibration
- Industrial Electronics Calibration
- LAN-XI Calibration

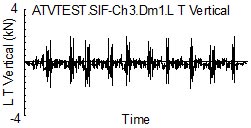 Figure 1. Ten laps of test track
Despite being a carefully controlled test track and a single driver, the variability in loading during each lap is easily seen in the figure.
From a fatigue damage perspective, is the data in Fig. 1 enough to characterize the service usage for the expected life of the component? This question can be answered by using the variability in the measured loading history to project what the expected fatigue damage and loading history would be if the loads were measured for longer time.
Analyzing the variability in the time domain for functions of load and time is not feasible or needed. In fatigue, the rainflow histogram of the loads is of more interest than the loading history itself since fatigue damage is computed from it.
Figure 1. Ten laps of test track
Despite being a carefully controlled test track and a single driver, the variability in loading during each lap is easily seen in the figure.
From a fatigue damage perspective, is the data in Fig. 1 enough to characterize the service usage for the expected life of the component? This question can be answered by using the variability in the measured loading history to project what the expected fatigue damage and loading history would be if the loads were measured for longer time.
Analyzing the variability in the time domain for functions of load and time is not feasible or needed. In fatigue, the rainflow histogram of the loads is of more interest than the loading history itself since fatigue damage is computed from it.
 Figure 2. Rainflow histogram
Two dimensional rainflow histograms contain information about both the load ranges and means. Figure 2 shows the rainflow histogram of the data from Fig. 1 in a To-From format. This type of histogram preserves mean stress effects which are usually important for fatigue analysis.
Data from Fig. 2 is plotted as a cumulative exceedance diagram in Fig. 3.
Figure 2. Rainflow histogram
Two dimensional rainflow histograms contain information about both the load ranges and means. Figure 2 shows the rainflow histogram of the data from Fig. 1 in a To-From format. This type of histogram preserves mean stress effects which are usually important for fatigue analysis.
Data from Fig. 2 is plotted as a cumulative exceedance diagram in Fig. 3.
 Figure 3. Exceedance diagram
The exceedance curve for the original loading history is shown on the left side of the diagram. If the test data were measured for 1000 laps (100 times longer), the distribution would be expected to be shifted to the right and have a similar shape. The dashed lines schematically show that higher loads would be expected for longer times. Although the exceedance diagram is easier to visualize, it looses valuable information about mean effects.
In this paper we show how the variability in a measured rainflow histogram can be used to estimate the expected rainflow histogram for longer times. This extrapolated histogram can then be used to reconstruct a new longer time history for testing or analysis.
Rainflow Extrapolation
Extrapolation of rainflow histograms was first proposed by Dressler [1]. A short description of the concept is given here. Readers are referred to reference 1 for the details. The rainflow histogram is treated as a two dimensional probability distribution. A simple probability density function could be obtained by dividing the number of cycles in each bin of the histogram by the total number of cycles. A new histogram corresponding to any number of total cycles can be constructed by randomly placing cycles in the histogram according to their probability of occurrence. However, this approach will be essentially the same as multiplying the cycles in the histogram by an extrapolation factor. But this is unrealistic. Even the same driver over the same test track cannot repeat the loading history. For example each time a driver hits a pot hole the loads will be somewhat different. This is clearly shown in the ten laps in Fig. 1. The peak load from a particular event will be placed into an individual bin in the rainflow histogram. During subsequent laps, this load will have a different maximum value and be placed into a bin in the same neighborhood as the first lap.
Figure 3. Exceedance diagram
The exceedance curve for the original loading history is shown on the left side of the diagram. If the test data were measured for 1000 laps (100 times longer), the distribution would be expected to be shifted to the right and have a similar shape. The dashed lines schematically show that higher loads would be expected for longer times. Although the exceedance diagram is easier to visualize, it looses valuable information about mean effects.
In this paper we show how the variability in a measured rainflow histogram can be used to estimate the expected rainflow histogram for longer times. This extrapolated histogram can then be used to reconstruct a new longer time history for testing or analysis.
Rainflow Extrapolation
Extrapolation of rainflow histograms was first proposed by Dressler [1]. A short description of the concept is given here. Readers are referred to reference 1 for the details. The rainflow histogram is treated as a two dimensional probability distribution. A simple probability density function could be obtained by dividing the number of cycles in each bin of the histogram by the total number of cycles. A new histogram corresponding to any number of total cycles can be constructed by randomly placing cycles in the histogram according to their probability of occurrence. However, this approach will be essentially the same as multiplying the cycles in the histogram by an extrapolation factor. But this is unrealistic. Even the same driver over the same test track cannot repeat the loading history. For example each time a driver hits a pot hole the loads will be somewhat different. This is clearly shown in the ten laps in Fig. 1. The peak load from a particular event will be placed into an individual bin in the rainflow histogram. During subsequent laps, this load will have a different maximum value and be placed into a bin in the same neighborhood as the first lap.
 Figure 4. Histogram variability
Figure 4 shows a rainflow histogram in a two dimensional view. Consider the event going from 2 to –2.5. Next time this is repeated it will be somewhere in the neighborhood of ( 2, -2.5 ) indicated by the large dashed circle. There is not much data in this region of the histogram and considerable variability is expected. Next consider the cycles from –2 to –1.5. Here there is much more data and we would expect the variability to be much smaller as indicated by the small dashed circle. Extrapolating rainflow histograms is essentially a task of finding a two dimensional probability distribution function from the original rainflow data.
For a given set of data taken from a continuous population, X, there are many ways to construct a probability distribution of the data. There are two general classes of probability density estimates: parametric and non-parametric. In parametric density estimation, an assumption is made that the given data set will fit a pre-determined theoretical probability distribution. The shape parameters for the distribution must be estimated from the data. Non-parametric density estimators make no assumptions about the distribution of the entire data set. A histogram is a non-parametric density estimator. For extrapolation purposes, we wish to convert the discrete points of a histogram into a continuous probability density. Kernal estimators [2-3] provide a convenient way to estimate the probability density. The method can be thought of as fitting an assumed probability distribution to a local area of the histogram. The size of the local area is determined by the bandwidth of the estimator. This is indicated by the size of the circle in Fig. 4. An adaptive bandwidth for the kernal is determined by how much data is in the neighborhood of the point being considered.
Statistical methods are well developed for regions of the histogram where there is a lot of data. Special considerations are needed for sparsely populated regions [4]. The expected maximum load range for the extrapolated histogram is estimated from a weibull fit to the large amplitude load ranges. This estimate is then used to determine an adaptive bandwidth for the sparse data regions of the histogram. Once the adaptive bandwidth is determined, the probability density of the entire histogram can be computed. The expected histogram for any desired total number of cycles is constructed by randomly placing cycles in the histogram with the appropriate probability. It should be noted that this process does not produce a unique extrapolation. Many extrapolations can be done with the same extrapolation factor so some information about the variability of the resulting loading history can be obtained.
Results for a 1000 times extrapolation of the loading history are shown in Fig. 5. It is easier to visualize the results of the extrapolation when the results are viewed in terms of the exceedance diagram given in Fig. 6. Two plots are shown in the figure. One from the data in Fig. 5 and another one representing a 1000 repetitions of the original loading history.
Figure 4. Histogram variability
Figure 4 shows a rainflow histogram in a two dimensional view. Consider the event going from 2 to –2.5. Next time this is repeated it will be somewhere in the neighborhood of ( 2, -2.5 ) indicated by the large dashed circle. There is not much data in this region of the histogram and considerable variability is expected. Next consider the cycles from –2 to –1.5. Here there is much more data and we would expect the variability to be much smaller as indicated by the small dashed circle. Extrapolating rainflow histograms is essentially a task of finding a two dimensional probability distribution function from the original rainflow data.
For a given set of data taken from a continuous population, X, there are many ways to construct a probability distribution of the data. There are two general classes of probability density estimates: parametric and non-parametric. In parametric density estimation, an assumption is made that the given data set will fit a pre-determined theoretical probability distribution. The shape parameters for the distribution must be estimated from the data. Non-parametric density estimators make no assumptions about the distribution of the entire data set. A histogram is a non-parametric density estimator. For extrapolation purposes, we wish to convert the discrete points of a histogram into a continuous probability density. Kernal estimators [2-3] provide a convenient way to estimate the probability density. The method can be thought of as fitting an assumed probability distribution to a local area of the histogram. The size of the local area is determined by the bandwidth of the estimator. This is indicated by the size of the circle in Fig. 4. An adaptive bandwidth for the kernal is determined by how much data is in the neighborhood of the point being considered.
Statistical methods are well developed for regions of the histogram where there is a lot of data. Special considerations are needed for sparsely populated regions [4]. The expected maximum load range for the extrapolated histogram is estimated from a weibull fit to the large amplitude load ranges. This estimate is then used to determine an adaptive bandwidth for the sparse data regions of the histogram. Once the adaptive bandwidth is determined, the probability density of the entire histogram can be computed. The expected histogram for any desired total number of cycles is constructed by randomly placing cycles in the histogram with the appropriate probability. It should be noted that this process does not produce a unique extrapolation. Many extrapolations can be done with the same extrapolation factor so some information about the variability of the resulting loading history can be obtained.
Results for a 1000 times extrapolation of the loading history are shown in Fig. 5. It is easier to visualize the results of the extrapolation when the results are viewed in terms of the exceedance diagram given in Fig. 6. Two plots are shown in the figure. One from the data in Fig. 5 and another one representing a 1000 repetitions of the original loading history.
 Figure 5. Extrapolated histogram
Table 1 gives the results of fatigue lives computed from various extrapolations of the original loading history. Fatigue lives represent the expected operating life of the structure in hours. A simple SN approach was employed in the calculations. Any convenient fatigue analysis technique may be used and can be combined with a probabilistic description of the material properties.
Table 1. Fatigue Lives
Figure 5. Extrapolated histogram
Table 1 gives the results of fatigue lives computed from various extrapolations of the original loading history. Fatigue lives represent the expected operating life of the structure in hours. A simple SN approach was employed in the calculations. Any convenient fatigue analysis technique may be used and can be combined with a probabilistic description of the material properties.
Table 1. Fatigue Lives
 Figure 6. Distribution of cycles and fatigue damage
One effective method to visualize the damaging cycles is to plot the distribution of cycles and material behavior on the same scale as shown in Fig. 6. Material properties are scaled so that they have the same units as the loading history and this plot represents the expected fatigue life under constant amplitude loading. The point of tangency of the two curves gives an indication of the most damaging range of cycles. The maximum load range cycles are not the most damaging in this history, rather the most damaging cycles for this loading history are at about ½ of the maximum load range in the extrapolated histogram.
Figure 6. Distribution of cycles and fatigue damage
One effective method to visualize the damaging cycles is to plot the distribution of cycles and material behavior on the same scale as shown in Fig. 6. Material properties are scaled so that they have the same units as the loading history and this plot represents the expected fatigue life under constant amplitude loading. The point of tangency of the two curves gives an indication of the most damaging range of cycles. The maximum load range cycles are not the most damaging in this history, rather the most damaging cycles for this loading history are at about ½ of the maximum load range in the extrapolated histogram.
 Figure 7. Inserting a VP cycle
An VP cycle ( r < c ) can be inserted into any PV reversal if c <= P and r > V. A VP cycle can not be inserted into a PV cycle of the same magnitude.
Figure 7. Inserting a VP cycle
An VP cycle ( r < c ) can be inserted into any PV reversal if c <= P and r > V. A VP cycle can not be inserted into a PV cycle of the same magnitude.
 Figure 8. Insertion of a PV cycle
Figure 8 shows the insertion of a PV cycle. An PV cycle ( c < r ) can be inserted into any VP reversal if r < P and c >= V. A PV cycle can not be inserted into a VP cycle of the same magnitude.
These two simple rules provide the basis for rainflow reconstruction. The process starts with the largest cycle either PVP or VPV. The next largest cycle is then inserted in an appropriate location in the reconstructed time history. After the first few cycles, there are many possible locations to insert a smaller cycle. All possible insertion locations are determined and one is selected at random.
Figure 8. Insertion of a PV cycle
Figure 8 shows the insertion of a PV cycle. An PV cycle ( c < r ) can be inserted into any VP reversal if r < P and c >= V. A PV cycle can not be inserted into a VP cycle of the same magnitude.
These two simple rules provide the basis for rainflow reconstruction. The process starts with the largest cycle either PVP or VPV. The next largest cycle is then inserted in an appropriate location in the reconstructed time history. After the first few cycles, there are many possible locations to insert a smaller cycle. All possible insertion locations are determined and one is selected at random.
