Mirrored blocks allow you to place the exact same block in multiple locations within a reliability block diagram (RBD) or a fault tree. This can be useful for many purposes, such as modeling bi-directional paths within a diagram and common cause failures. Mirroring is accomplished by adding blocks to a mirror group. Mirror groups are resources that can be shared among analyses and can be managed via the Resource Manager. Blocks that belong to a mirror group have a square at the lower left corner of the block; the appearance of the indicator and its caption are configurable.
Mirrored blocks are treated as fully equivalent multiple instances of a single block, rather than considered as an original and copies. The failure times and all maintenance events are identical for every block in the mirror group. Any changes made to the properties of a block in a mirror group will apply to all other blocks in the mirror group.
Using mirrored blocks guarantees that multiple blocks will exhibit the same behavior (e.g. failures...) and experience the same action (e.g. corrective maintenance, inspections...) simultaneously. Entering the same properties for different blocks in a diagram does not ensure that these blocks will act like mirrored blocks. For example, because of the randomness, blocks that have the same failure distribution and the same parameters could still fail at different times when performing a simulation.
Common cause failures have traditionally been handled using the Beta, MGL, Alpha and BFR models. BlockSim has a simpler and more effective approach to handling common cause failure that relies on the use of mirrored blocks. Therefore, the traditional common cause failure analysis methods will not be discussed in this article. The following example illustrates the BlockSim approach.
Consider the following example in which Event A could cause both an X Failure (if it happens along with a B event) and a Y Failure (if it happens along with a C event).
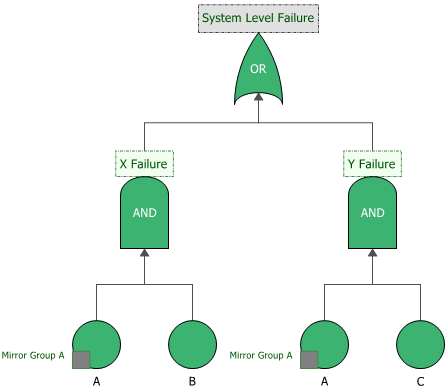

You can use mirrored blocks to indicate that the two A events are actually the same event and to specify that if event A occurs then Failures X and Y could occur.
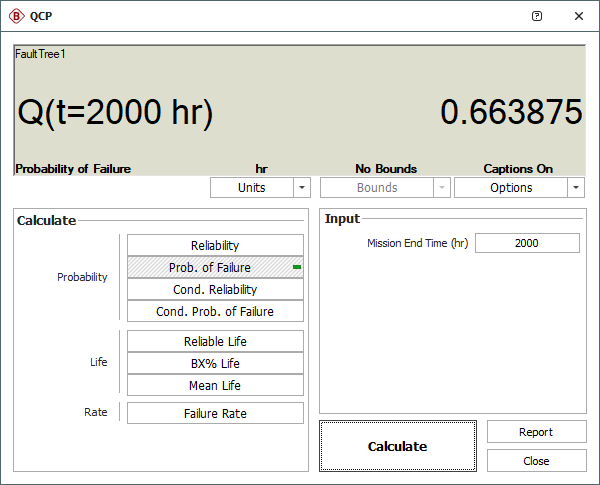
The probability of a system level failure occurrence can be found using the Quick Calculation Pad as follows.
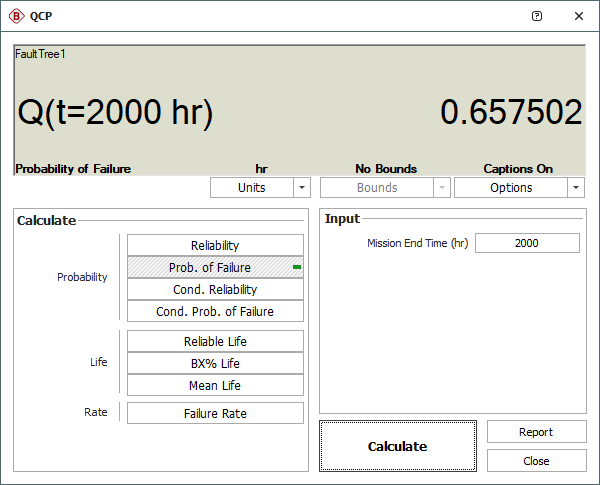
If the two events A in this fault tree example were not mirrored, the results would have differed, as the following figure shows.